나만의 AI 에이전트 만들기
자비스를 아십니까
어릴 적 아이언 맨 3 영화를 봤던 기억이 난다. 스토리 중에서 주인공 토니 스타크의 AI 비서 '자비스'가 그때는 그렇게 멋져보였다.
당시 나는 C++를 배우던 알고리즘 학원에 다니고 있었는데, 간단하게나마 비슷한 것을 만들어보고 싶었다. 그래서 특정 문자열을 입력하면 미리 정의된 문장들 중 하나를 랜덤하게 출력하는 프로그램을 만들었던 기억이 어렴풋이 남아 있다. 지금 생각해보면 단순한 장난감 수준이었지만, 그때의 나는 나름대로 ‘AI’를 만들었다고 생각했던 것 같다.
LLM 붐
최근에는 Agentic AI의 활용도가 급격하게 늘어나며 뉴스에서는 너나 할 것 없이 LLM에 대한 이야기 뿐이다. 휴학 후에 할게 아무것도 없었던 나는 로컬 LLM이나 돌려볼까 하는 생각에 LLM을 돌릴 수 있는 방법에 대해 찾아보았다.
llama.cpp는 로컬에서 LLM 추론을 빠르게 할 수 있도록 도와주는 경량 LLM 실행 엔진이다.
llama.cpp는 GGUF 형식의 모델을 지원한다. Hugging Face에서 쉽게 사람들이 훈련 시켜놓은 모델들을 찾을 수 있었다. 처음으로 시도해본 모델은 Llama-3.2-3B-Instruct-IQ3_M 이었다.
LLM 모델을 공유하는 허깅페이스 커뮤니티가 커지면서 모델 네이밍에 컨벤션이 생긴 것 같다. 3B는 모델 파라미터 갯수, IQ3_M은 양자화를 어떻게 했는지인 것 같다. (사실 잘 모르겠다)
GPT왈 모델 파라미터는 지식이 얼마나 많은지, 양자화는 지식을 얼마나 정확하게 기억하는지라고 생각하면 된다고 한다.
llama-cli.exe --model .\models\Llama-3.2-3B-Instruct-IQ3_M.gguf
이 명령어 하나면 나도 AI를 공짜로 부려먹을 수 있다!
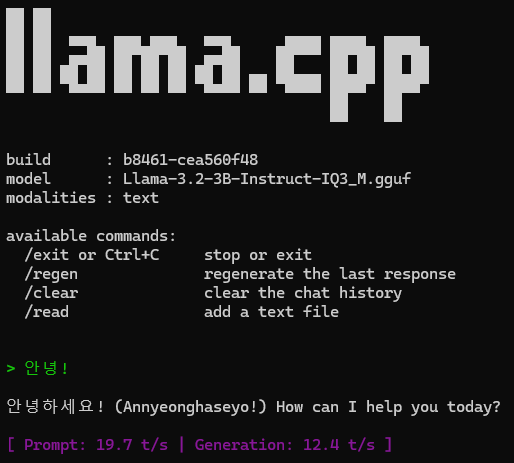
이 아이 외국인이다.
나중에 보니 모델별로 지원하는 언어가 다 따로 있더라...
그런데 그램 노트북에서 CPU로 돌리니 모델이 입을 여는 속도가 느리다.

또 양자화로 인해 능지박살이 일어난 것인지, 아니면 원래 저랬는지 가끔씩 이상한 문자가 응답에 나타나기도 했다.
왠만해선 쓸만한 모델을 돌리면서 생성 속도를 높게 뽑아내려면 GPU달린 PC가 필수인 것 같다. 전역하면 AI 스테이션 하나 맞춰야겠다.
마침 집에 게임용으로만 쓰던 RTX 2070 Super가 달린 데스크탑이 하나 있었고, PC로 더 좋은 모델을 돌려보았다. GPT왈 Qwen3.5-4B.Q4_K_M 이게 찢어지게 가난한 내 고물 PC 수준에 딱 맞다고 한다.
llama-cli.exe -ngl 999 --model Qwen3.5-4B.Q4_K_M.gguf
GPU를 사용하려면 -ngl 파라미터를 저렇게 주라고 하더라. 이걸 몰라서 GPU 달아놓고 CPU만 쓰고 있었다.
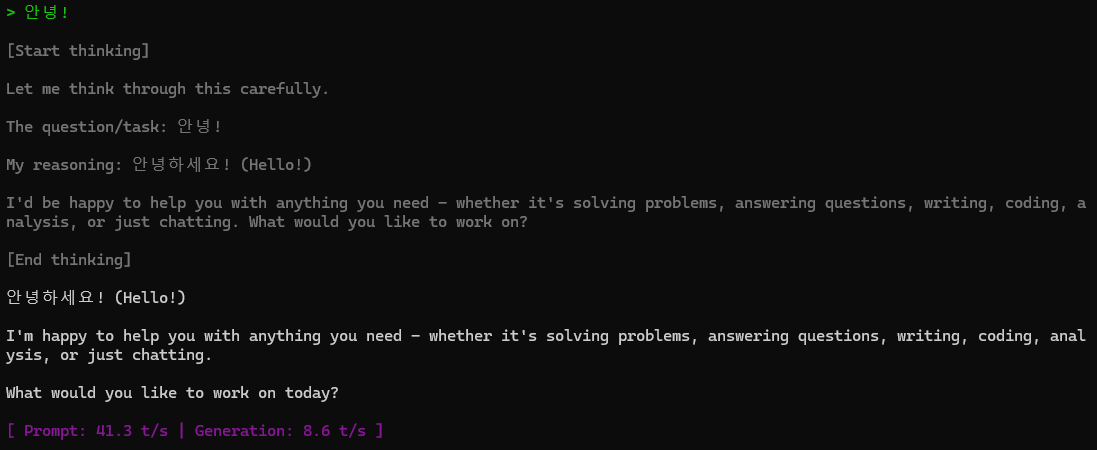
Qwen이라는 모델은 생각 이라는 것을 하고 나서 답변을 해주는 기능이 있다고 한다. 확실히 더 빠르고 퀄리티 있는 답변을 돌려준다.
안녕 한마디를 대답하기 위해 이렇게 깊게 고민한다.
나만의 AI 에이전트 만들기
여기까지 LLM을 돌려보고나니 내 컴퓨터에서 돌아가는 AI가 이정도 능지라면 내 어릴적 꿈을 실현 시킬 수 있을 것만 같은 느낌이 들었다.
침대에 누워 AI에게 마이크로 말해서 작업을 시키고, 음성으로 피드백을 받는 시스템을 만들어 보고 싶어졌다. (침대에 누워있는 것이 가장 중요하다)
일단 키보드를 쳐서 AI랑 소통하는 이 치명적이게 비효율적인 프로세스를 개선하기 위해 AI에게 입과 귀를 달아주어야 한다.
옛날 프로젝트에서 썼던 Whispher에다가 TTS만 붙여도 입과 귀는 이식할 수 있다. 여기에 MCP까지 붙여서 API 호출을 가능하게 하고 라즈베리파이에 서보 모터를 달면 "자비스, 방 불 꺼줘" 까지도 가능 할 것 같다는 생각이 머리를 스쳤다. 진짜 생각만 해봐도 존나 멋있다.
당장 이 짓거리를 하기 위해 클로드 Pro 버전을 결제한다.
AI 에이전트 개발을 위한 AI 에이전트 활용
LLM 준비하기
이번 프로젝트에서 가장 중요한 부분인 능지를 담당할 LLM을 실행하고, 입/출력을 서빙할 수 있는 서비스가 필요하다. Claude의 Cowork를 사용해 먼저 llama.cpp를 docker로 래핑하였다. 이후 다른 서비스들이 붙어도 docker-compose up 하나로 실행 시킬 수 있도록 하기 위함이다.
llama.cpp API 서버를 테스트하기 위해 llama.cpp pre-built binaries중 Windows와 내 CUDA 버전에 맞는 바이너리 파일을 받고, llama-server.exe를 적절한 인자와 함께 실행 시켜 테스트 해보았다. 나의 경우에는 Windows CUDA 13.1 버전이었다.
C:\Users\obelisk>nvidia-smi
Mon Mar 30 13:44:42 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 591.55 Driver Version: 591.55 CUDA Version: 13.1 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 2070 ... WDDM | 00000000:01:00.0 On | N/A |
| 30% 38C P8 25W / 210W | 971MiB / 8192MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
실제로 사용할 코드에는 이미 빌드된 ghcr.io/ggml-org/llama.cpp:server-cuda 이미지를 다운받아 모델만 마운트 시켜 도커로 실행했다.
이 글은 작성 중 입니다.